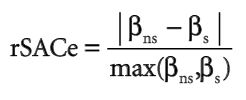Franklin, Janet. “Moving beyond static species distribution models in support of conservation biogeography.” Diversity and Distributions 16.3 (2010): 321-330.
DOI: 10.1111/j.1472-4642.2010.00641.x
SDM extrapolates species locations in space based on correlations of presences with environmental variables. Nonetheless, most of the SDM are static, assuming species locations data used for modeling are representative of its true distribution, and distributions are in equilibrium with environment factors. In order to meet the needs of conservation biogeography, static SDM needs to move to incorporate dynamic processes determining species distribution. Franklin therefore discussed three strategies of increasing complexities for SDM incorporating process models, namely 1) to incorporate models of species migration to understand the ability of species to occupy suitable habitat in new locations; 2) to link landscape disturbance and succession to suitability; 3) to link suitability models with habitat dynamics and population dynamics. Generally, migration models account for species dispersal and establishment, but not account for interactions with other species. Both population viability models and community dynamics models account for dispersal and competition. However, there will always be trade-offs between using complex, mechanistic versus simple, empirical models for environmental change forecasting. By linking all modeling complexities, the framework could be powerful to understand the potential interactions and population persistence. But good knowledge of species interactions and life history is required. Most notions in this paper are at conceptual level, though he brought up a really good point to combine dynamics into SDM. However, in many cases we use SDM is to compensate for our lack of knowledge on the ground. Hopefully we can see some specific applications that include dynamic variables into species commonly used SDMs, and maybe a comparison can be made in terms of which model is more compactible with dynamic processes.