Bird, T. J., Bates, A. E., Lefcheck, J. S., Hill, N. A., Thomson, R. J., Edgar, G. J., et al. (2014). Statistical solutions for error and bias in global citizen science datasets. Biological Conservation, 173(C), 144?154. http://doi.org/10.1016/j.biocon.2013.07.037
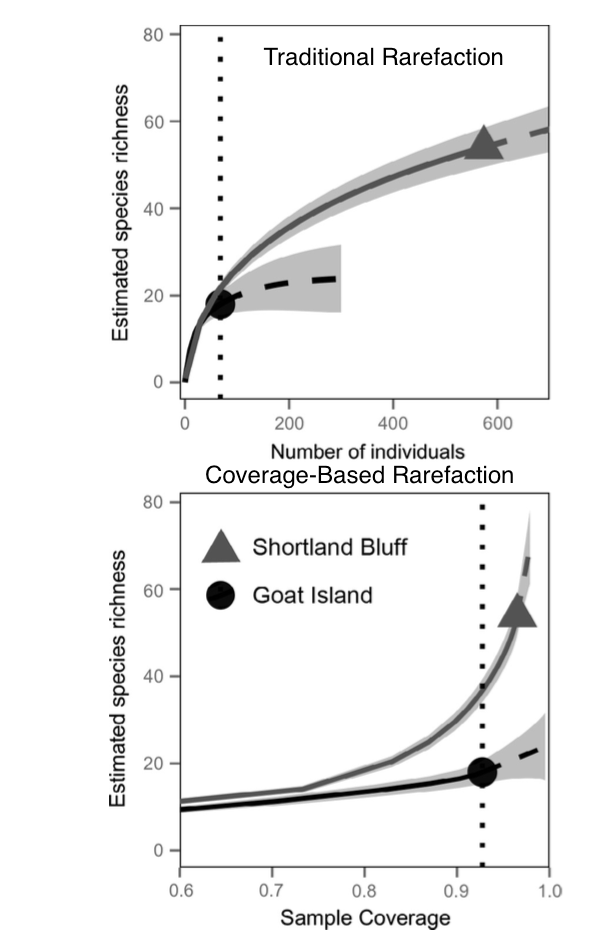
Citizen science has been gaining traction because of its ability to be both an outreach and data collection tool, however there is a serious concern about bias in the data. This bias can be avoided by implementing trainings and stricter sampling protocols, or through statistical processes more often used to correct sampling bias in SDM. The primary issues in citizen science data are greater variability and sampling bias. Fortunately, many of the same statistical methods for accounting for bias in normally gathered occurrence data can be used for citizen science data. We’ve discussed many of them in more detail in class, so I will only focus on the more novel techniques. One method they recommend is accounting for variation between surveyor’s skill levels or biases by using mixed-effects models where surveyor identification is a random effect. Because citizen science data is usually less sparse than normal occurrence data, another common technique is to use an occupancy-detection model, which is based on other citizen scientists’ data. Similarly, when calculating biodiversity or species richness, you can account for under sampling by using a measure of sample “completeness”, similar to conventional rarefaction curves, but which extrapolate species richness before limiting the samples, resulting in higher species richness measures (see Figure). While these statistical methods allow for some correction, they can not completely correct for bias in citizen science data as well as proper training of volunteers and protocols. AS citizen science becomes more well-used, a field of comparing citizen science data to expert data is growing, which will hopefully be able to inform and better design citizen science experiments to mitigate these issues from the beginning.