Elith, J., & Graham, C. H. (2009). Do they? How do they? WHY do they differ? On finding reasons for differing performances of species distribution models. Ecography. http://doi.org/10.1111/j.1600-0587.2008.05505.x
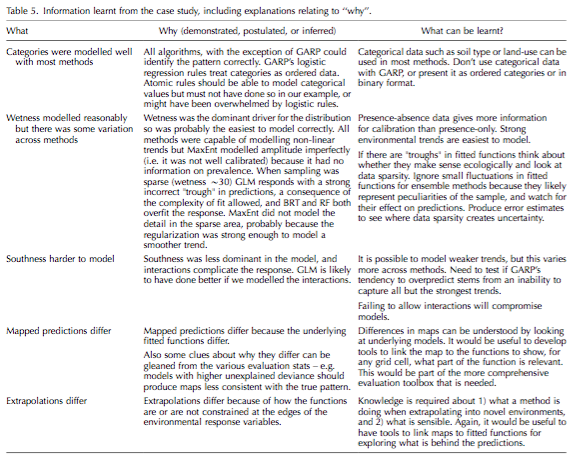
With the expansion of SDM has come an increasing emphasis on machine-learning models, however there are few resources available for newcomers to help guide which models to choose for which application, or end goal. As a first step in creating such a guide, Elith & Graham use a simulated plant presence-absence data set and assessed the success of five algorithms to achieve three common goals in SDM: 1) understanding the relationship between a species and its environment, 2) creating a map of habitat suitability, and 3) extrapolating to new environmental conditions. The five algorithms were a generalized linear model, boosted regression trees, random forests, MaxEnt, and GARP, the last two using presence-only data. They compared each algorithm’s performance for each of the three applications of SDM, using four different measures of statistics. Their results are summed up in the table below, and I’m not going to rehash them here. An important conclusion they drew from their comparisons, however, are that the researcher must have an understanding of the algorithm they are using and the ecological background of their system in order to choose the best model for their application and system. For example, GARP does not model categorical variables well, and presence only models may not be well calibrated depending on the range of suitability. I found it interesting that, even though these algorithms still represent a ‘black box’, a user’s understanding of their strengths and weaknesses will allow the user to better interpret the somewhat subjective output in choosing a model of ‘best fit’ for their chosen goal.