
Jiménez‐Valverde, Alberto, et al. “Discrimination capacity in species distribution models depends on the representativeness of the environmental domain.” Global Ecology and Biogeography 22.4 (2013): 508-516. DOI: 10.1111/geb.12007
Discrimination capacity, or the effectiveness of the classifier as was discussed in class, is usually the only characteristic that is assessed in the evaluation of the performance of predictive models. In SDM, AUC is widely adopted as a measurement for discrimination capacity, and what is important for AUC is the ranking of the output value, but not their absolute difference. However, calibration or how well the estimate probability of presence represents the observed proportion of presences is another aspect of the performance of model evaluation.
Jiménez‐Valverde et. al. thus examined how changes in the distribution of probability of occurrences make discrimination capacity is a context-dependent characteristic. Through simulation, they found that a well-calibrated model, where the probability of randomly chosen positives have higher S then randomly chosen negatives (P) is equal to S, will not attain high AUC value, which is 0.83. and confirmed that discrimination depends on the distribution of the probabilities. Figure 2 shows some extreme cases demonstrating trade-offs between discrimination capacity and calibration reliability. When a model is well calibrated, dots should line up along the solid line.
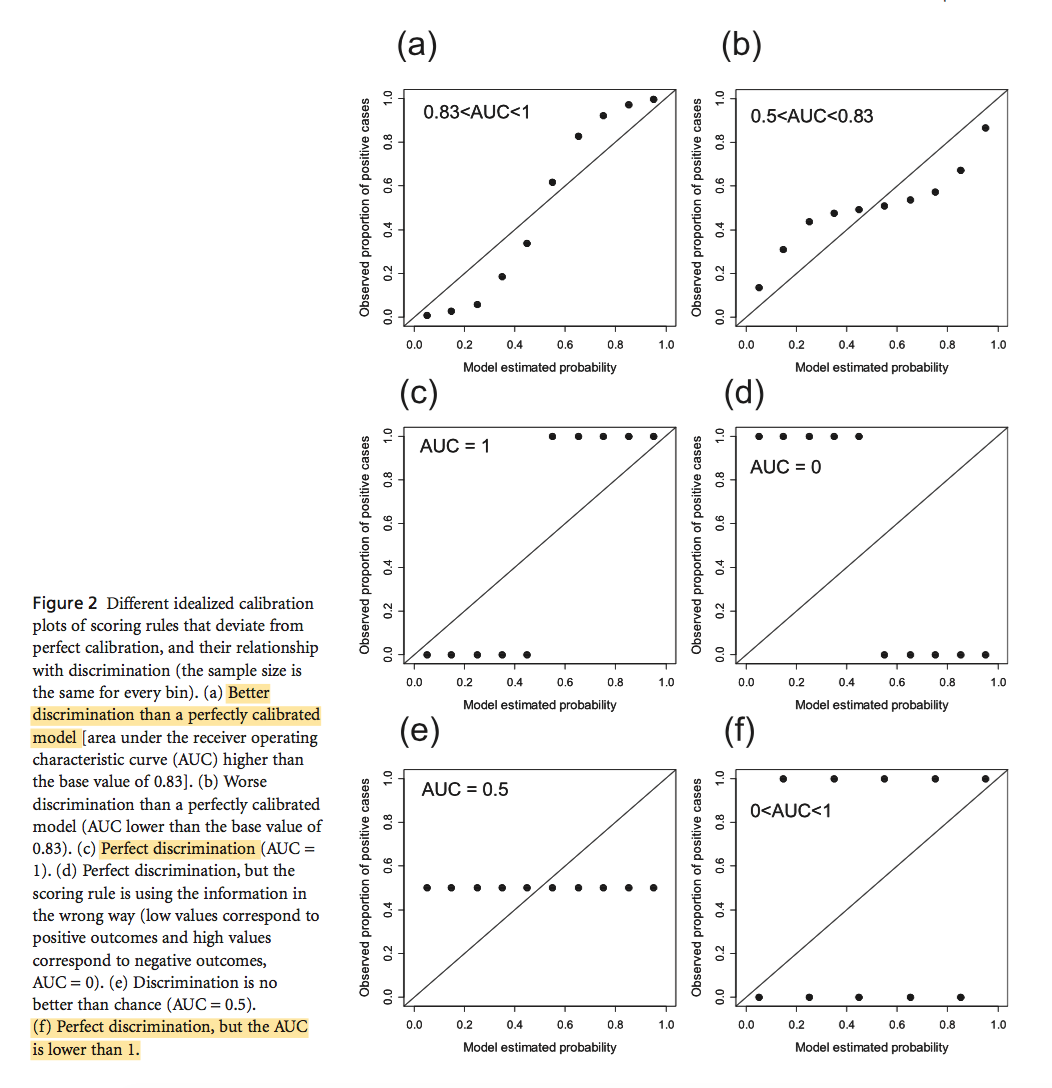
This paper not only well explained the difference between discrimination and calibration and why the increase of one compromises another, it also pointed out two implications in the field of SDM: first, it explains the devilish effect of the geographic extent, which is the reason for the negative relation between the relative occurrence area and discrimination capacity; second, discrimination may not be used to compare different modeling techniques for the same data population and to generalize conclusions beyond that population. It is noteworthy to aware limitations and conditions when evaluating our own models. One practical way is to not report AUC alone, but also be accompanied with information about the distribution of scoring system and, if possible, the model calibration plots.