Higa, M., et al. (2015). “Mapping large-scale bird distributions using occupancy models and citizen data with spatially biased sampling effort.” Diversity and Distributions 21(1): 46-54.
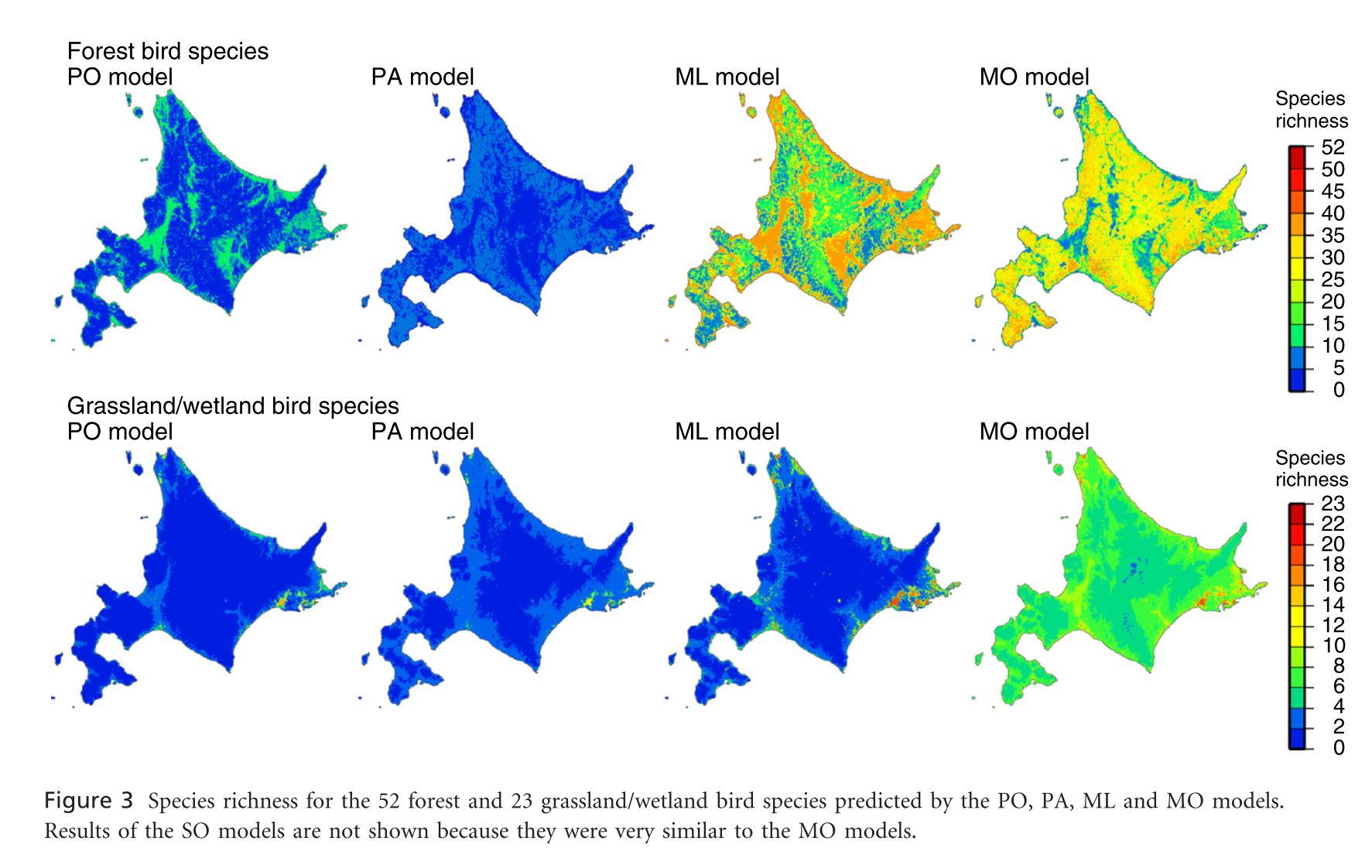
Citizen science data offers the ability to collect large amounts of species distribution data that would be impossible for a researcher to gather otherwise. This data can, however, suffer from issues of inconsistent data quality across the range (because of inconsistency in the expertise of citizens) and spatial sampling bias. The authors consider multiple SDM methods and their performance when applied to an aggregated data set collected by professionals and citizens with spatially biased sampling effort. Records of bird species presences were sorted into 4 categories: point census by experts, line census by experts, observation with other methods by experts, and observation with other methods by citizens. Environmental covariates were land cover and elevation. Models employed were presence-absence (PA) or presence-pseudoabsence (PO) (depending on available data) logistic regression, MaxLike, and two types of occupancy models. One type of occupancy model analyzed each species individually (SO) while another analyzed multiple species in the same model (MO). Both of these models depend estimation of latent occupancy (a Bernoulli variable) and detection/non-detection (a Bernoulli variable based on occupancy and observation probability from detection/non-detection data. The SO models for 18 forest bird species and two grassland/wetland bird species did not converge. Detection probabilities for all species were below 1 and differed by observation type (line census by experts>other methods by citizens and point census by experts>other methods by experts). Probability of presence for forest species decreased with forest area for PO and ML models while it increased with forest area in PA and especially occupancy models. Grassland/wetland species probability of presence increased with grassland and/or wetland area across all models though species richnesses predicted by PA, PO, and ML were lower than occupancy models. Both types of occupancy models (SO and MO) generally agreed. The authors claim that this work demonstrates the weakness of MaxLike and presence-only logistic regression in the face of spatial sampling bias. They put forward occupancy models that explicitly model detection as an easier and equally effective method as, if not a more effective method than, accounting for bias through similarly biased absence data (PA). Though this study lacks any actual evaluative measures (beyond the assumption that forest species should be more likely to occur in larger forests), the process of occupancy modeling seems nonetheless very promising and should certainly be tested more broadly.