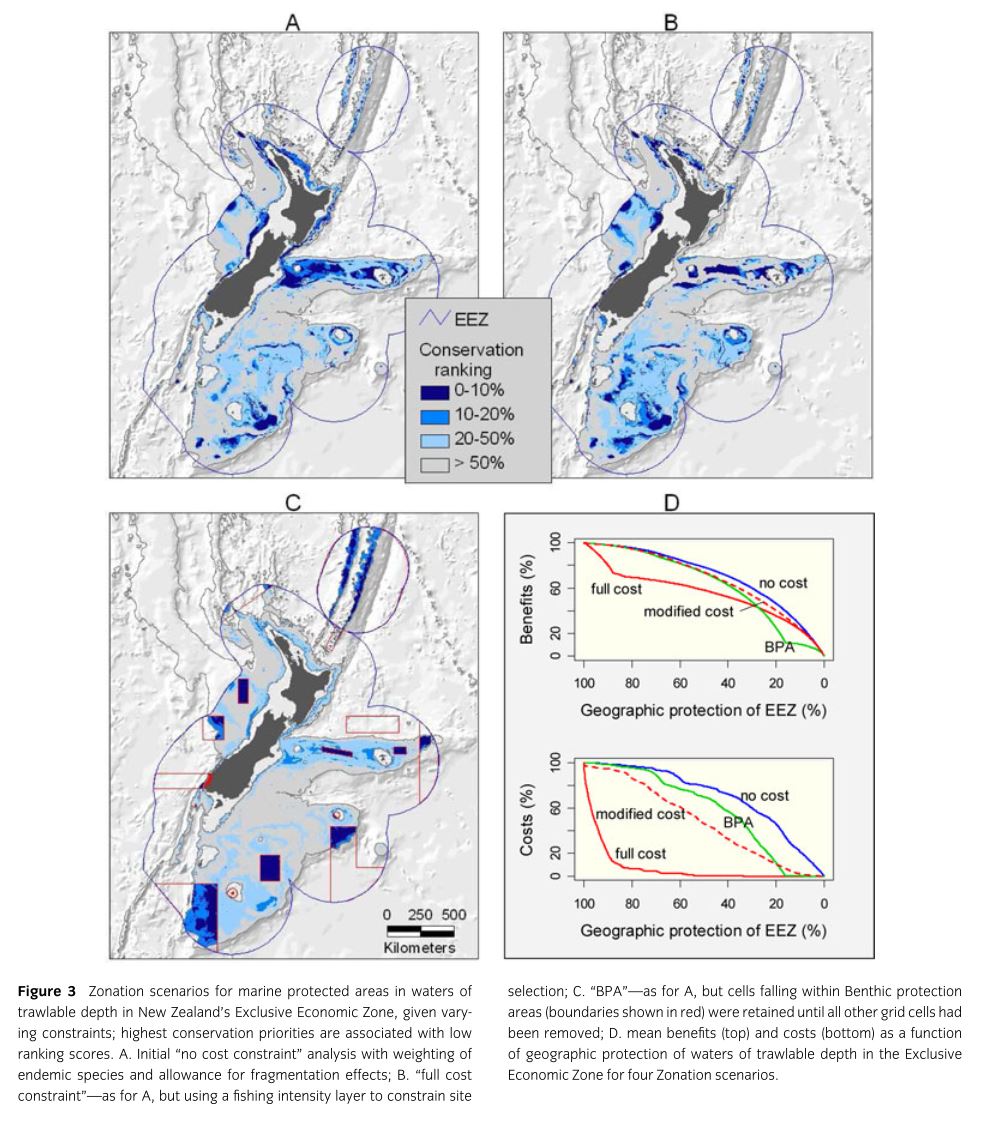
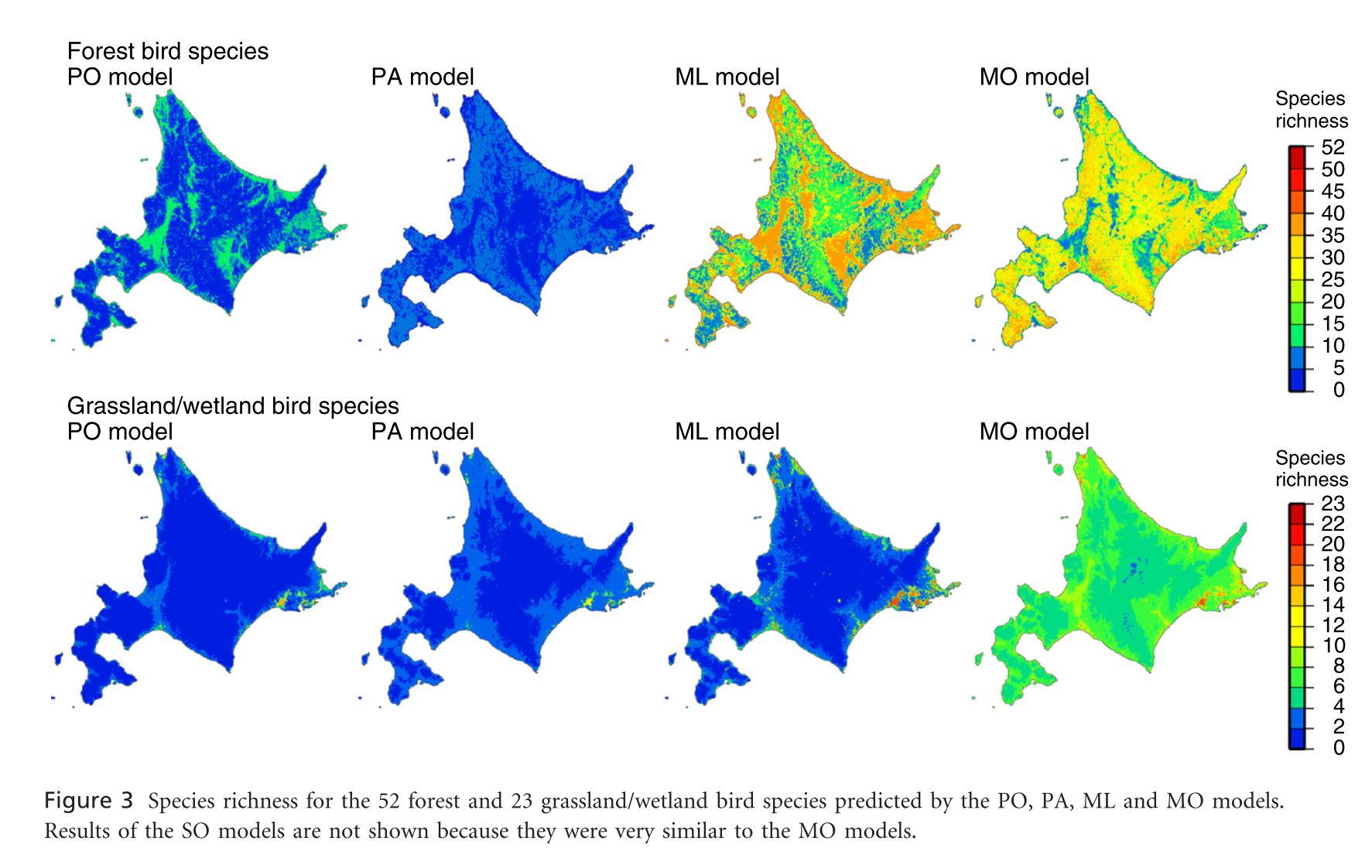
Leathwick, J., et al. (2008). “Novel methods for the design and evaluation of marine protected areas in offshore waters.” Conservation Letters 1(2): 91-102.
Declines in marine biodiversity due to human exploitation, especially in fisheries, pose a serious threat to our oceans. Marine Protected Areas (MPAs) are instituted in some areas in order to reverse these losses. Various methods are used to identify and justify new candidates for MPA status. This paper serves as a proof of concept, using the oceanic waters of New Zealand’s Exclusive Economic Zone, for a new method based on Species Distribution Modeling. Patchy locality data on 96 commonly caught fish species were interpolated across the EEZ using a Boosted Regression Trees based SDM based on environmental covariates functionally relevant to fish. 17,000 trawls were used for model fitting and 4,314 were used for model evaluation. Because of the zero inflated nature of the data two BRT models (the first was fit to presence absence in the trawl and the second to log of catch size given presence). After evaluation these models were used to make environment-based predictions of catch per unit effort for each species for 1.59 million 1km2 grid cells. These predictions were employed for delineation of MPAs using the software Zonation. The software begins with preservation of the entire grid and then progressively removes cells that cause the smallest marginal loss to conservation value. The implementation used here attempts to retain high-quality core areas for all species. Of 96 predicted fish distributions 19 endemics were given higher priority weighting. Neighborhood losses were also assessed based on fish life histories such that the loss of some proportion of neighboring cells devalued the focal cell. The final component of the Zonation analysis is cost of preservation. The authors analyze outcomes under 4 cost scenarios: (1) “No cost restraint” equal costs for all cells so analysis is solely driven by species, (2) “full cost constraint” costs for grid cells varied based on fishing intensity, (3) “modified cost constraint” in which the costs of grid cells are rescaled from the “full cost constraint”, (4) “BPA” in which Zonation was used to assess the cost and value of a recently implemented set of Benthic Protection Areas in the waters around New Zealand.
Depth, temperature, and salinity contributed most to the predictive models. Models showed excellent predictive ability for presence/absence (Mean AUC=0.95, range= 0.86-0.99) but predictive ability for catch size was more variable (mean correlation= 0.534, range=0.05-0.82). “No cost constraint” analysis show that preservation of 10% of offshore parts of the EEZ would protect on average 27.4% of the geographic range of each of the analyzed fish species (46.4% if 20% is preserved). Use of neighborhood constraints identifies far more clumped groups of cells for protection. “Full cost constraint” analysis only shared 2/3 of its top 10% cells with the no constraint model but it would only provide slightly lower conservation value (mean=23.4% of each species range protected) with no loss of current fishing activity. “Modified cost constraint” analyses produced a range of intermediates between these two extremes. BPA areas (which comprise 16.6% of the trawlable EEZ) would protect on average 13.4% of species ranges if no fishing was allowed. Clearly all other scenarios outperform the current implementation of the BPA.