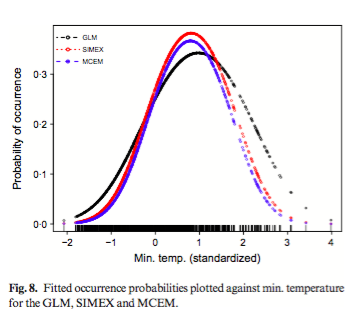
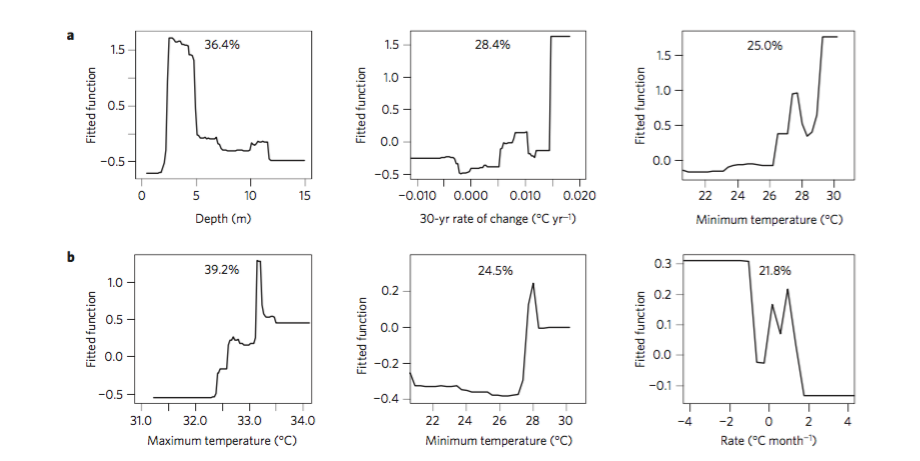
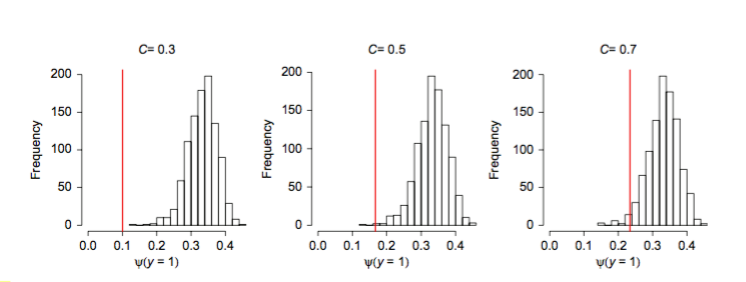
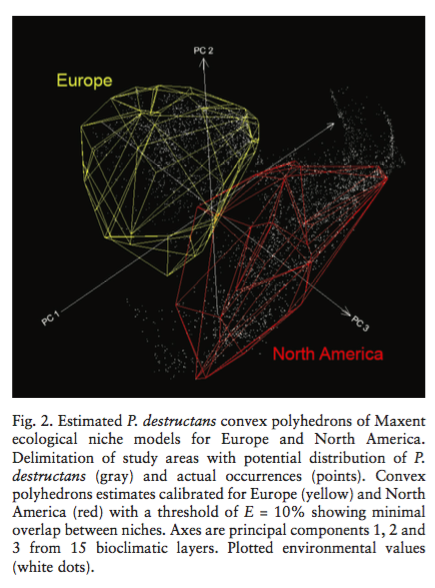
Kitchin, R., 2014. Big Data, new epistemologies and paradigm shifts. Big Data & Society, 1(1), p.2053951714528481.
This article argues that the explosion in the production of Big Data and the advent of new science epistemologies where questions are born from the data rather than testing a theory by analyzing data has far-reaching consequences to how research is conducted. One section evaluates whether the scientific method is rendered obsolete with the production of Big Data. Instead of making educated guesses about systems, constructing hypotheses and models, and testing them with data-based experiments, scientists can now find patterns in data without any mechanistic explanation at all. But in some fields, this doesn’t really matter. For example, in online retail stores Person A might be known to like item A and most people that like item A also like item B. In this situation, the mechanism does not really matter for the retail company to sell more items. Thus, mining the entire population’s behavior for prediction trumps explanation for the retail markets. But the result is an analysis that ignores important effects of culture, politics, policy, etc. So expanding these ideas to the field of biology might include a bioinformatist that view the complexity of biology in a much different way that an experimental molecular biologist. To an informatist, data can be interpreted free of context and domain-specific expertise but it might be low on logical interpretation.
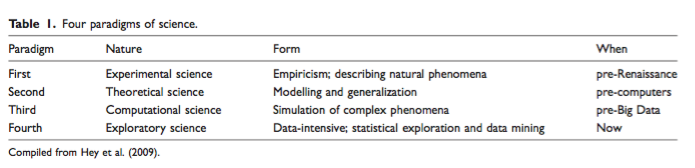
It seems to me that the majority of ecologists are aware of the concerns that Kitchin raises and would probably side with him on most points, especially when thinking about mechanisms causing patterns rather than settling with knowing the correlations that coincide with them. Nevertheless, I think it was a good read and one that helped me contextualize some disagreements between Big Data and production of new science.