Bocsi, Tierney, et al. “Plants’ native distributions do not reflect climatic tolerance.” Diversity and Distributions (2016).
—
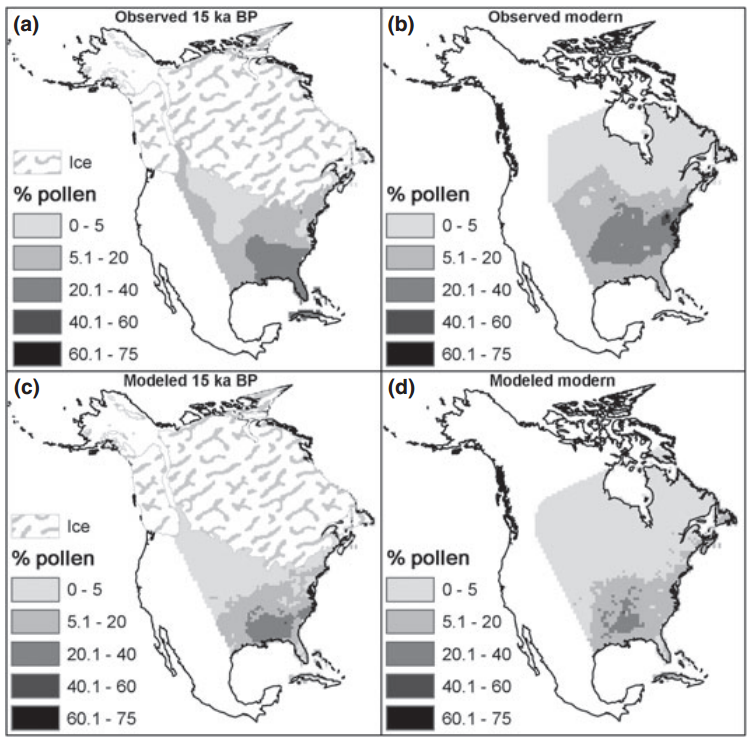
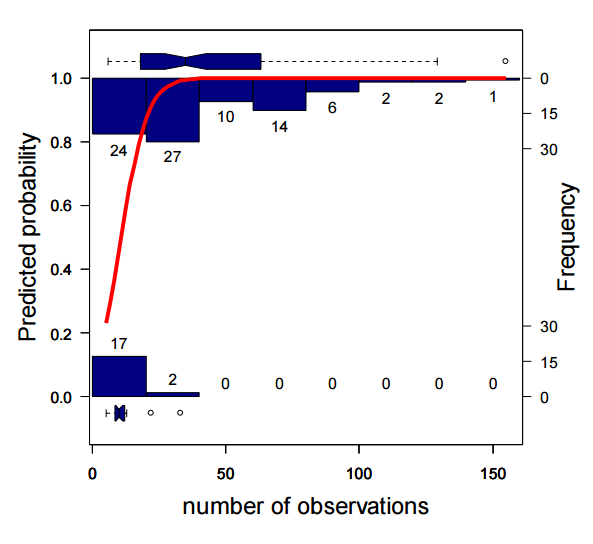
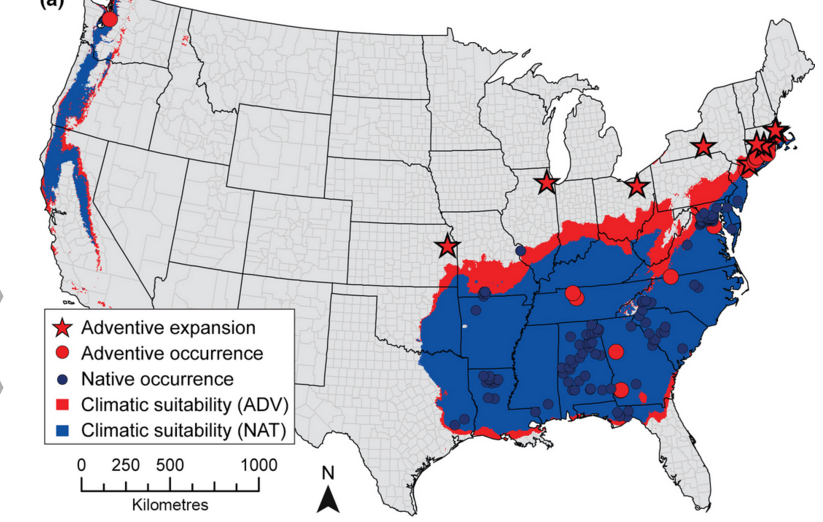
This paper is related to the last one I posted on in that it argues that a core assumption of species distribution models is violated, and that this violation could influence the applicability of species distribution models. The often-violated assumption is that of range equilibrium, and the full exploitation of environments which the species can persist. That is, the assumption that species occurrences in space capture niche boundaries. To address how often species can persist outside of their predicted niche boundaries, the authors used data on 144 US plants that occurred in their native range, and that were introduced through ornamental use (“adventive”). They Googled plant names + “garden” or “for sale” to determine if the plant was ornamental. They pulled county-level data from multiple sources, including GBIF, and a bunch of herbaria, arguing that herbarium collections identify the native range, and the Biota of North America Program (BONAP) to get at adventive occurrences outside of the native range. The authors trained MaxEnt models on each species in both native and native+adventive ranges on 3 variables (annual precipitation, minimum January temperature and maximum July temperature). The data needed to consist of at least 10 native occurrence points, and at least 1 adventive point. The authors found that the inclusion of adventive occurrences expanded the predicted suitable geographic range for 86% of the species examined. There was a negative relationship between the size of the native range and the amount of niche expansion. Model accuracy was high on average (> 0.9 ), and was consistently higher for models trained on only the native occurrence points. The authors claim that the increase in the size of the geographic range as a function of including adventive occurrences is evidence that the assumption that occurrence points represent the realized niche is overly optimistic.