
Fukuda, S., & De Baets, B. (2016). Data prevalence matters when assessing species’ responses using data-driven species distribution models. Ecological Informatics, 32, 69-78.
DOI: 10.1016/j.ecoinf.2016.01.005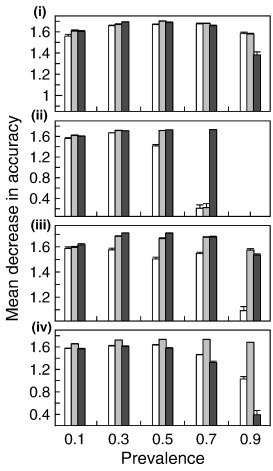
It is widely known that data quality and quantity can influence model accuracy. Studies have also concluded that data prevalence can have an effect on model accuracy, though no studies have examined how data prevalence may influence the habitat suitability inferences drawn from the model. This study looks at how data prevalence affects model accuracy and habitat information retrieved for the SDM using virtual species with varying prevalence. Virtual species were generated from three habitat variables and hypothetical habitat suitability. Data sets were simulated for each species with prevalence of 0.1, 0.3, 0.5, 0.7, and 0.9. Three species distribution models were built for each data set. Model accuracies varied between model type with random forest performing the best, followed by SVM, and then FHSM. Model accuracy responded differently to prevalence between each model type. The error for FHSM models increased as prevalence increased. For random forests the error was influenced more by the data sets than the prevalence. SVM model error exhibited no trend with varying prevalence. Variable importance differed across dataset and prevalence. In general the data models overestimated habitat suitability except for in the case of prevalence equal to 0.1. This study demonstrated the effects of data prevalence on model accuracy. Dependence of model accuracy on data prevalence varied by model. These results may demonstrate a level of robustness of these models to varying data prevalence. When considering which model to use for a species distribution data prevalence may be an important factor to consider as depending on the model uses prevalence can influence the accuracy of the model and the inferences a researcher may draw.