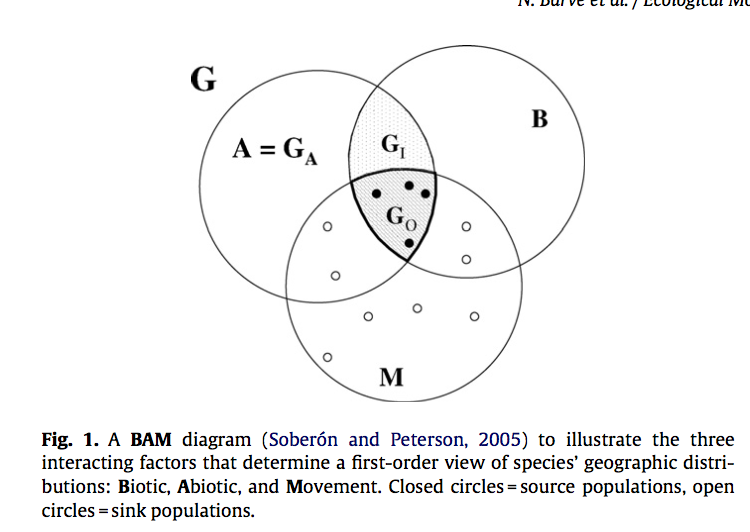
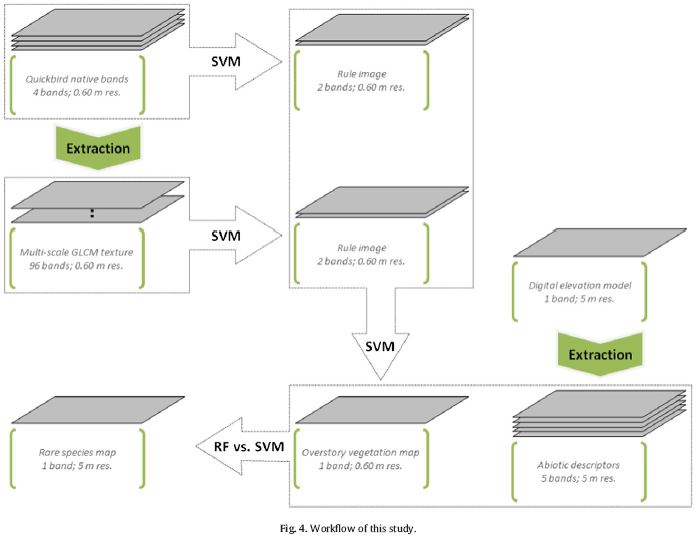
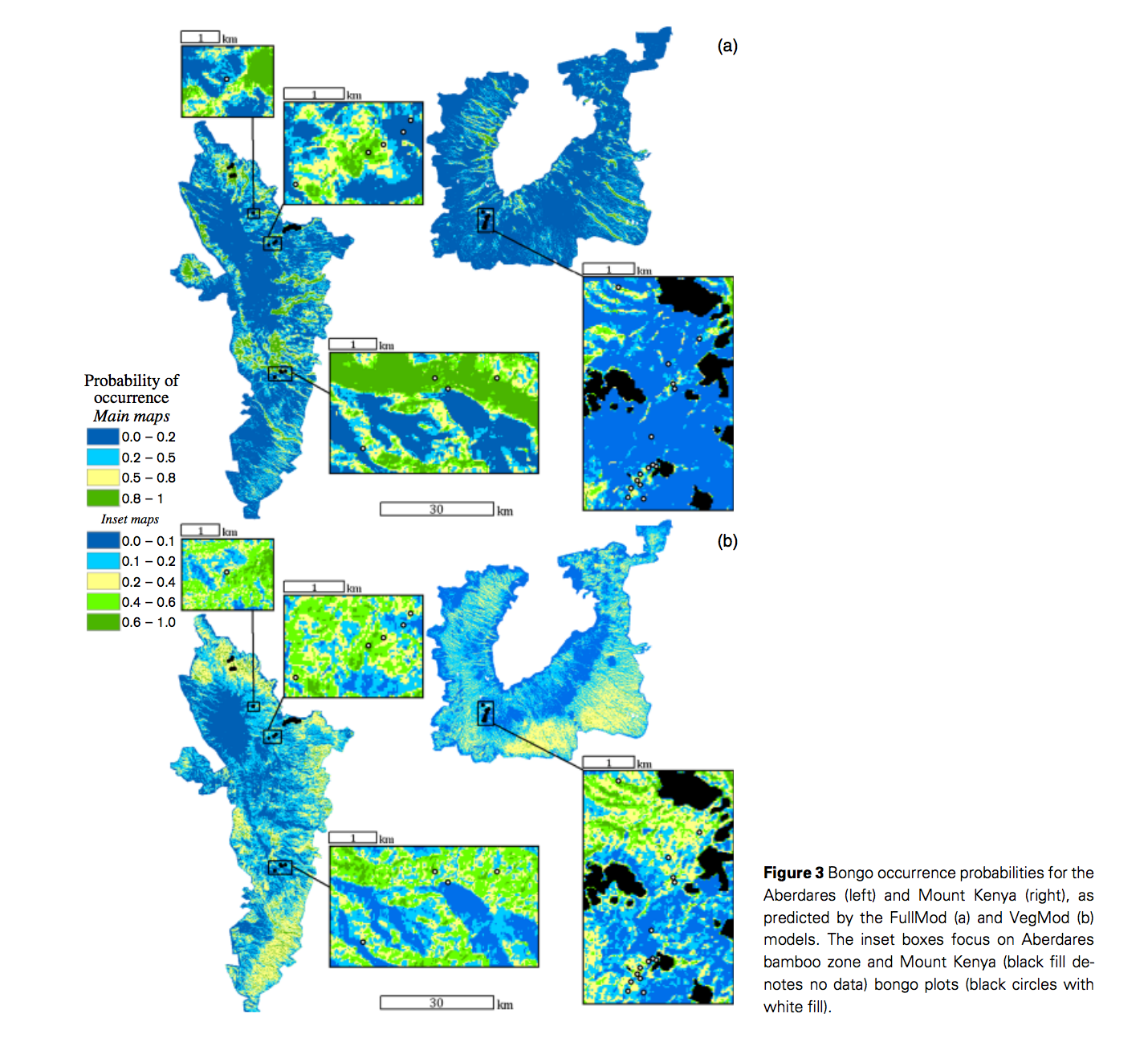
Estes, L. D., et al. “Predictive distribution modeling with enhanced remote sensing and multiple validation techniques to support mountain bongo antelope recovery.” Animal Conservation 14.5 (2011): 521-532.
DOI: 10.1111/j.1469-1795.2011.0045
Transferable predictive distribution model is based on predictors describing the ranges and scales of relevant environmental gradients It is able to predict distributions of habitat use so that to facilitate species recovery. Estes et al used logistic regression modeling approach for a rare species, mountain bongo, to understand their special ecology of habitat use and to assist species recovery in Mont Kenya and Aberdares. One common problem for species distribution modeling for rare species is data limitation. They used remote sensing derived quantitative vegetation structure maps, moisture, and ruggedness as transferable habitat predictors. Totally 31 logistic linear regression models were constructed and tested using AIC values. A DNA analysis was applied to verify observations of bongo. They also used independent observations from Mont Kenya to assess the transferability of the model. The models showed ruggedness was the most important variables for habitat use, indicating their strong preference to difficult terrain. Bongos also prefer sites that closer to the patrol route of park rangers and that have complex vegetation structures. However, predictors are sources of model bias when transfer models between habitats, such as over-parameterization and spatio-temporal variation in species-environment relationships. Estes et al stated that bongo habitat associations should not differ greatly between two habitats, but the environmental variations between mountains caused the limited transferability of the mountain. As predictors, elevation is indirect as oppose to vegetation and moisture, which are directly related to habitat use. A direct measures of predation risk and food plant abundance and using better-sourced remote sensing imagery would improve this model, which is highly dependent on remote sensed data.
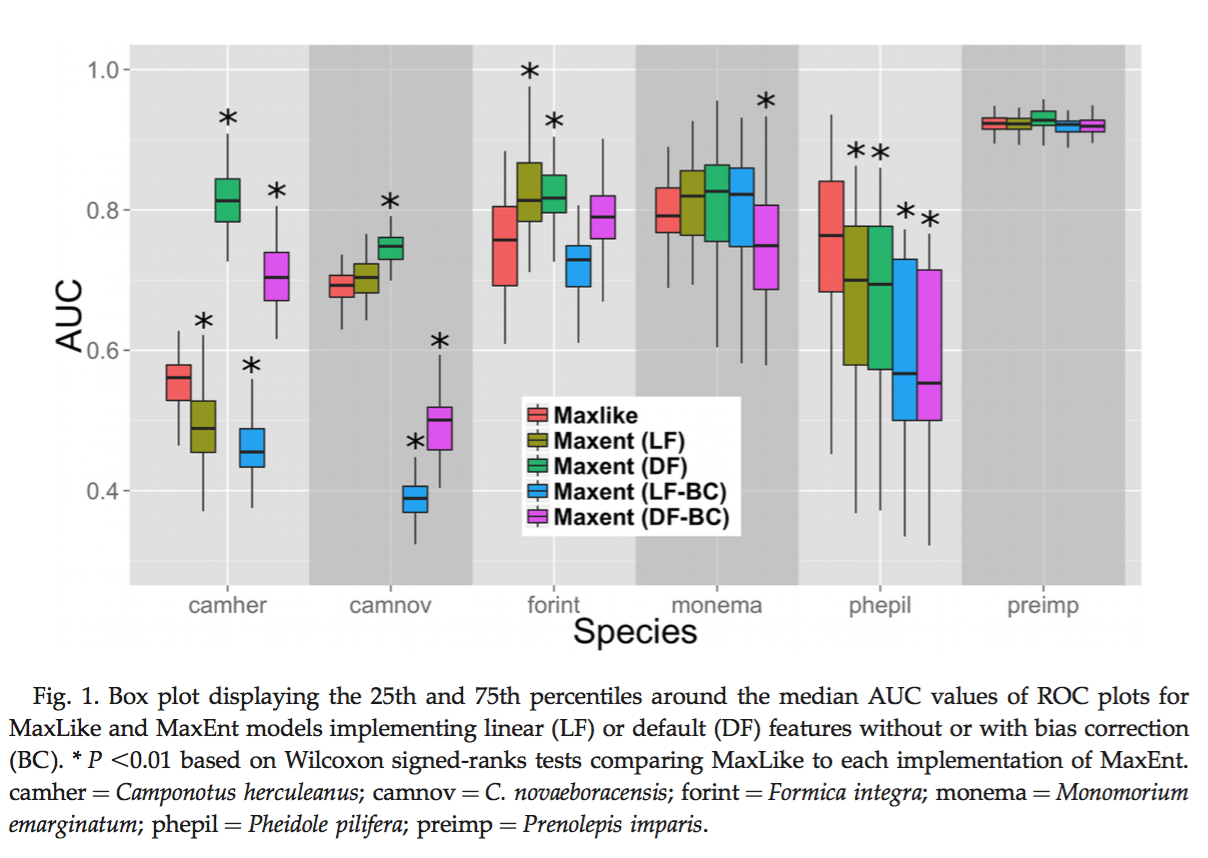 Fitzpatrick, M. C., N. J. Gotelli, and A. M. Ellison. 2013. MaxEnt versus MaxLike: empirical comparisons with ant species distributions. Ecosphere 4(5):55. http://dx.doi.org/10.1890/ES13-00066.1
Fitzpatrick, M. C., N. J. Gotelli, and A. M. Ellison. 2013. MaxEnt versus MaxLike: empirical comparisons with ant species distributions. Ecosphere 4(5):55. http://dx.doi.org/10.1890/ES13-00066.1