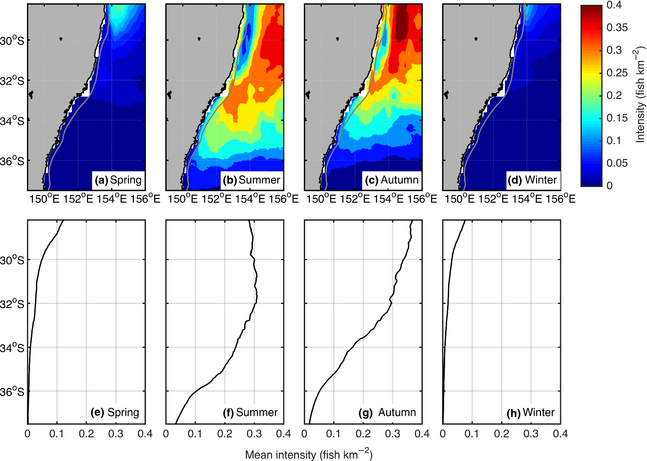
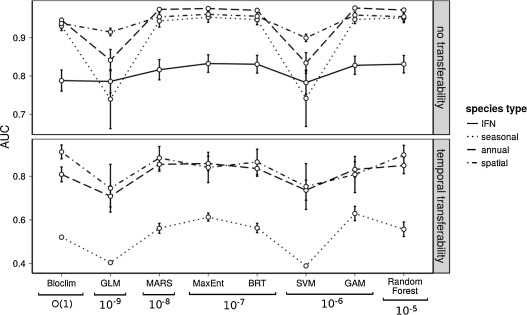
Bland, L. M., Collen, B., Orme, C. D. L. and Bielby, J. (2015), Predicting the conservation status of data-deficient species. Conservation Biology, 29: 250–259. doi: 10.1111/cobi.12372
One-sixth of the >65,000 species assessed by the IUCN are classified as data deficient (DD) due to a lack of information on taxonomy, geographic distribution, population status, or threats. Field surveys of DD species is not feasible, but large amounts of life history, ecological, and phylogenetic information are available can be combined for a comparative study of extinction risk based on species trait data.
The authors address the following questions:
- What are the relative abilities of 7 different ML methods (classification trees, random forests, boosted trees, k nearest neighbors, support vector machines, neural networks, and decision stumps) to predict extinction risk in terrestrial mammals?
Random forests, boosted trees, support vector machines, and neural networks performed particularly well. Classification trees and k nearest neighbors performed relatively poor.
- How accurately can those methods predict current geographical patterns of extinction risk?
The presented models were less likely to assign narrow-ranging non-threatened species and wide-ranging threatened species to their correct status.
- Using the models obtained, what is the predicted level of extinction risk faced by DD species?
313 of 493 (63.5%) of DD species are predicted as threatened, this increases the global proportion of threatened terrestrial mammals from 22% to 27%.
- How do our findings change current geographical patterns of extinction risk for terrestrial mammals?
Not really
Methods: The authors collated a database of 4461 terrestrial mammals classed as either non-threatened, threatened, vulnerable, endangered, critically endangered or data deficient. Additionally, life history traits biogeographic distribution and habitat suitability were collected for each mammal. ML models (to predict threatened/non-threatened status) were developed using all mammals, along with separate models of rodents, bats, primates, and carnivores to explore the taxonomic transferability of ML predictive accuracy. Highly correlated and low variance variables were removed before fitting any models. The training/testing (75/25) data set did not include any DD species. All models were tuned to maximize AUC values. The Youden index was used to set the probability threshold to distinguish between the two classes. Predicted (from the best global ML) threatened species’ range maps were then compared to current global patterns of extinction risk.