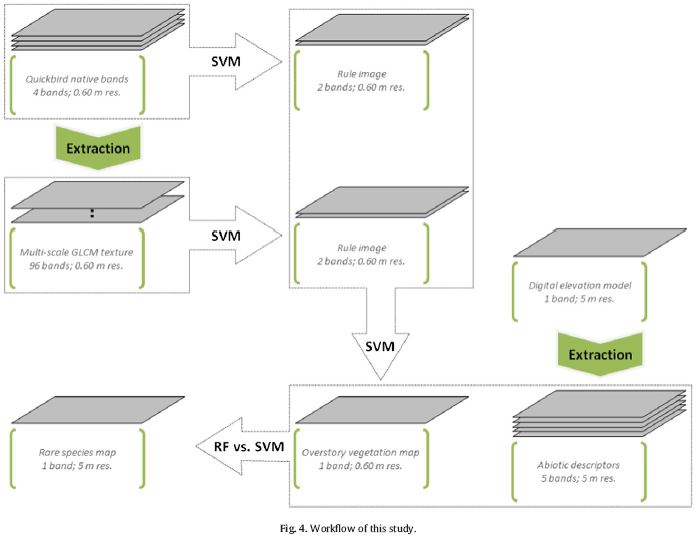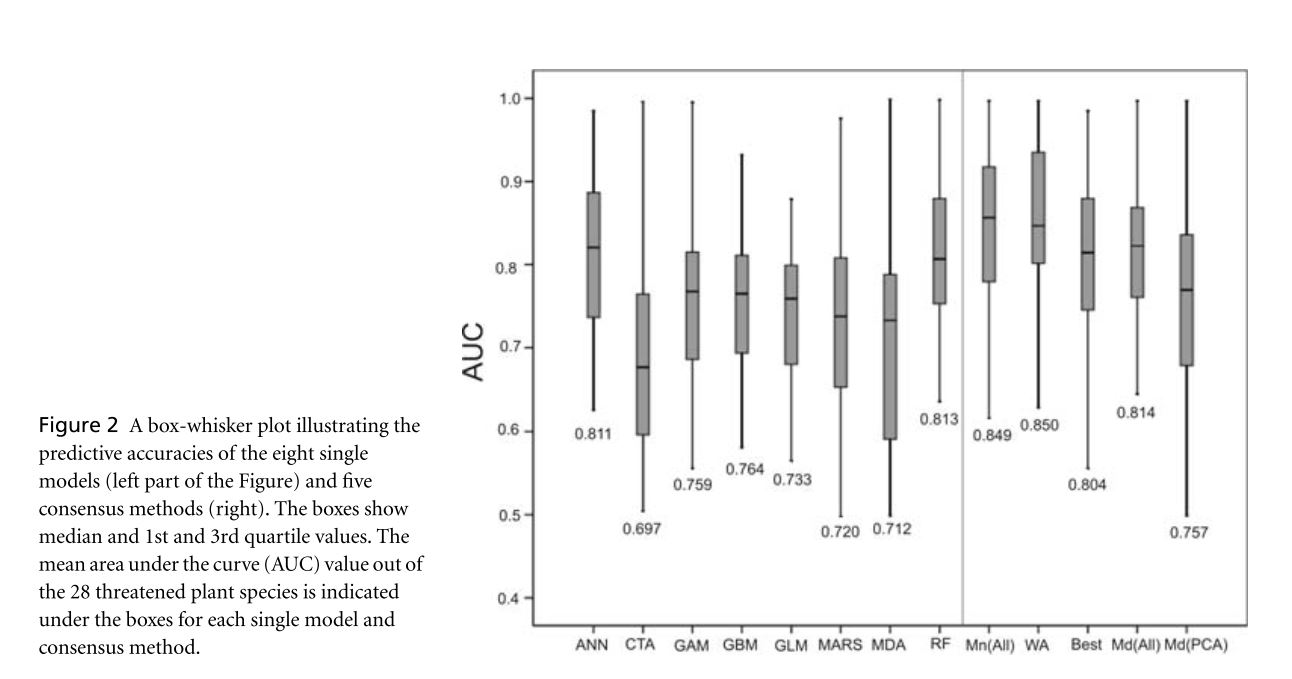
DOI: 10.1111/j.1365-2486.2006.01256.x
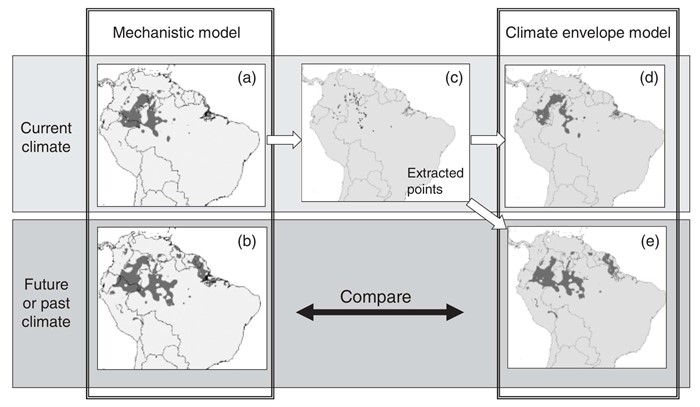
Hijman and Grahams objective was to evaluate whether Climate Envelope Models (CEM) are as successful in predicting species distribution under future climate change scenarios as it is in predicting current species distribution. They evaluated CEM ability by comparing CEM predictions with predictions obtained from Mechanistic Models (MM, which are based on an understanding of species physiology while CEMs use known geographic locations of a species to infer on their environmental requirements). They evaluated data from 100 plant species for past, current, and future distributions, by comparing MM results with four different CEM that covered a range of statistical approaches: BioClim, Domain, GAM, and Maxent and used range size, overlap index, false positive rate, and false negative rate to determine how well species distribution with CEM corresponds with MM (Generally illustrated in Fig. 1). The concern is that some CEMs may be unsuitable to predict species ranges under future climate because 1) cannot be tested using independent model training and testing data sets (i.e. no observed data for future scenarios and 2) a statistical model in which the inferred environmental requirements may not be suitable for truly classifying suitable vs. unsuitable environments. Hijmans suggests to compare results from CEM with MM, because using MM will model species distribution using physiology independent of climate. However, the only problem with MM is that physiology data is not always easy to gather. There was considerable variation between CEM and ability to reproduce the predictions from MM. Maxent and GAM provided good estimates for range shift with climate change. Domain underestimated range size. Bioclim underestimates future ranges, so would be considered a conservative approach, for example for reserve planning. Don’t even go with Domain, because it was considered too sensitive to the number of environmental variables used to predict species distribution. They came to the conclusion that some CEMs are reasonably good at predicting species dristributions under a climate change scenario.
In this paper, to assess species distribution changes in response to climate change, nonclimatic effects were eliminated. This is not very realistic however, because species distributions is likely influenced by both biotic and abiotic factors. It would be interesting to take biotic factors into account, because most likely species interactions with one another may be indirectly linked to changes in distribution driven by abiotic factors (one would persist and the other may not?). Also, applying this to vertebrate data, and even more interestingly, a migrating species, would be a great next step for using CEM to predict future species distribution.
(Figure caption: Approach used to evaluate the ability of climate envelope models to predict species distributions under different climates. A mechanistic model is used to predict the potential distribution for a species under current (a) and future (or past) (b) conditions (light gray = not suitable, dark gray = suitable). Points are extracted randomly from the area deemed currently suitable for the species (c). These points are used in the climate envelope model for current (d) and future (e) conditions. The statistical model is evaluated through a comparison of (b) and (e).)