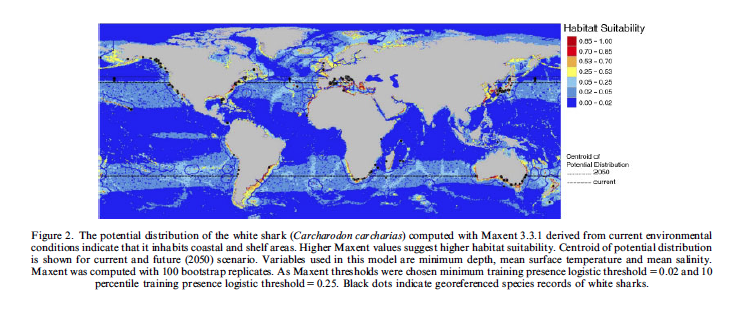
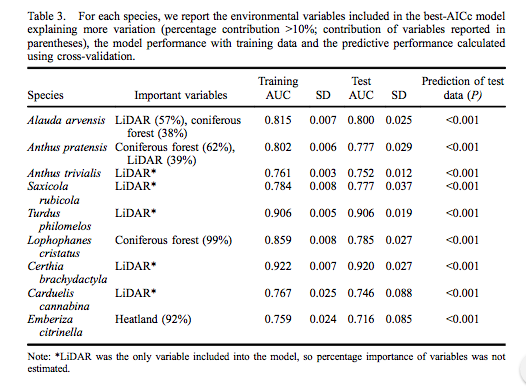
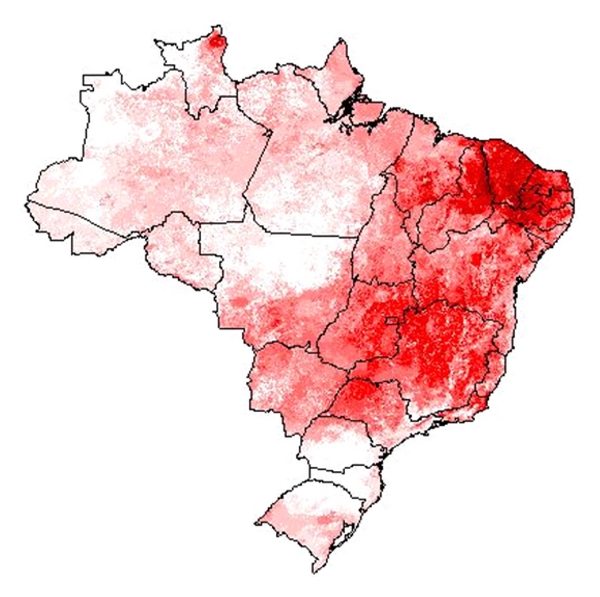
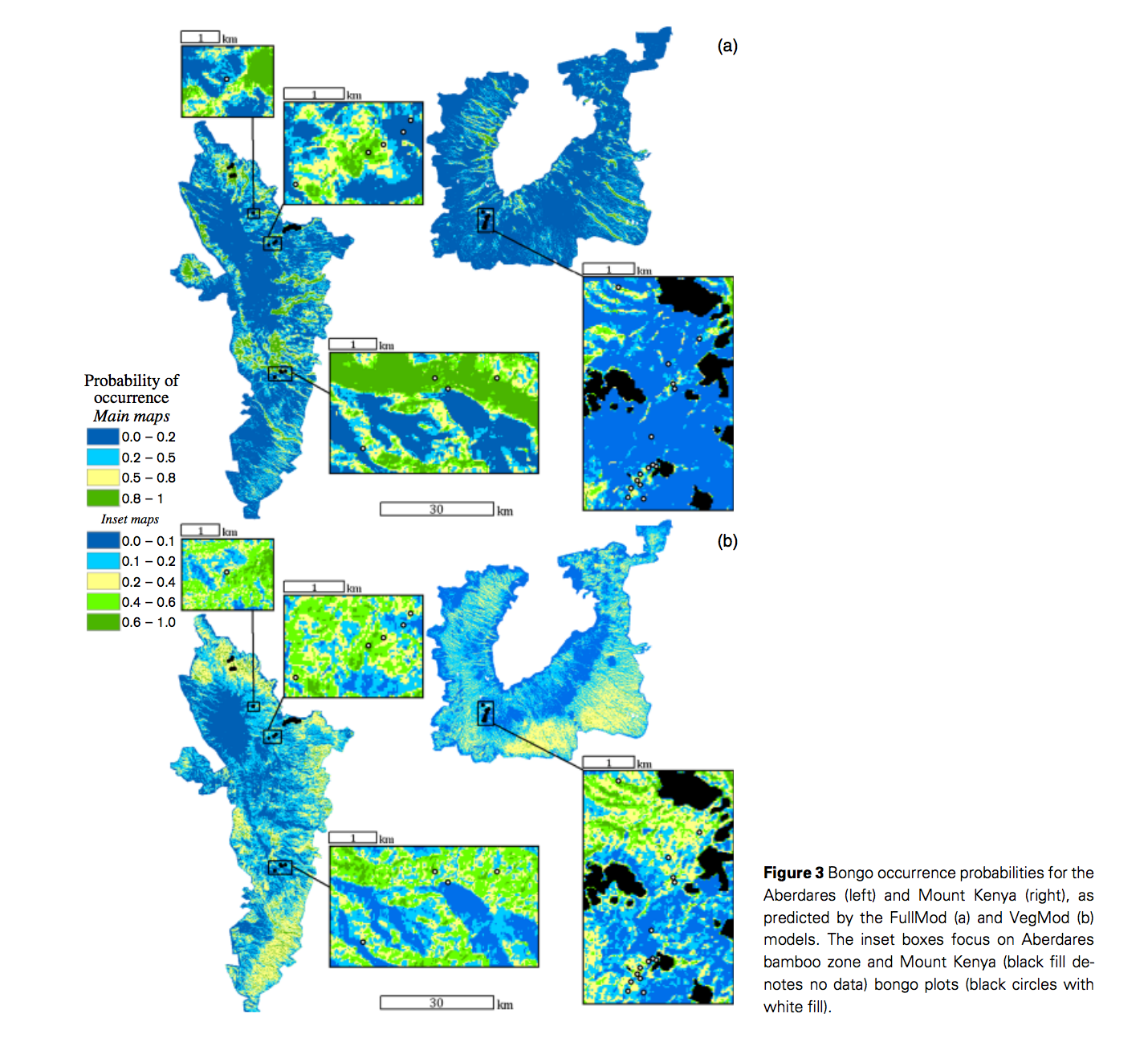
Lennon, J. J., et al. (2011). “Are richness patterns of common and rare species equally well explained by environmental variables?” Ecography 34(4): 529-539.
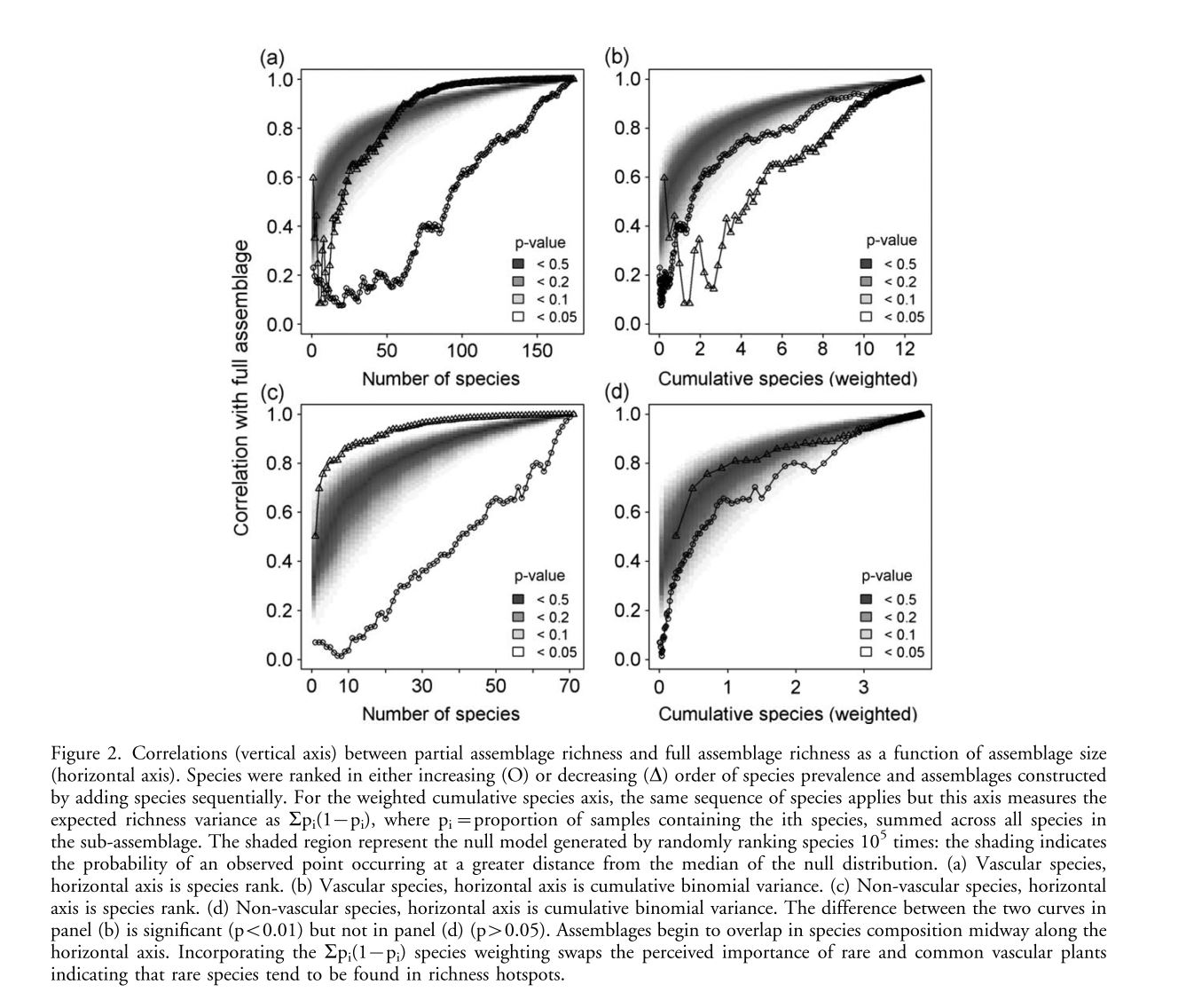
Species richness predictions based on environmental models rely on the assumption that richness patterns of both common and rare species respond similarly to environmental variables. Additionally the contribution of rare species to variation in richness may be swamped out by the contributions of more common species meaning that environmental factors identified as important for richness may just be important for this small subset of influential species. This phenomenon may be driven by the skewed distribution of species commonness, namely that rare species are rarer than common species are common. So in a small assemblage of rare species there will be many areas with 0 richness, while a similar size assemblage of common species will have fewer areas of uniform richness (fewer 0s but still not many maximums). This paper focuses on showing how species along the rare-common continuum differ in environmental associations using grassland plant and lichen species along an environmental gradient on the Scottish island of South Uist. Hypothesis: Rare species associated with rare environments and common species with common environments and rare and common species differ in relation to environmental variable. 217 roughly evenly spaced samples were taken along a 200mX2162m grid. At each site species composition along with soil and environmental variables were recorded. To determine the effect of rarity on contribution to richness sub-assemblages were built sequentially from most common and least common species, correlated richness values for each individual sub-assemblage with the total assemblage and plotted them against rank order of species addition. In order to account for the relative capacity of species to contribute on the basis of their prevalence alone correlations were also plotted against the expected variance of the given sub-assemblage richness pattern. These correlation plots were compared to an iterated null model. Common species contribute more to species richness patterns than rare species. When expected variance due to prevalence is taken into account this pattern reverses for vascular plants with rare species more associated with higher richnesses. The rescaling of non-vascular plants that there may not be a clear relationship between rarity and richness. GLMMs with Poisson errors and exponentially spatially structured random affects fitted using penalized quasi-likelihood were fit to each pattern of building species assemblages, with species richness as response. Small assemblages of rare species are poorly explained by environmental covariates as compared to common species. For vascular plants richness vs. environment associations of common species differ from those for rare species. For non-vascular plants models fit to more common species fit better likely due to them being easier to predict. Similar GLMMs were fit to the relationship between the species richness of each assemblage along the rare-common axis as a function of the environmental rarity and extremity of the sample (in environmental space). For vascular plants, rarer species were significantly positively associated with extreme and rare environments while commoner species were associated with only moderate environments. For non-vascular plants, only common species were associated with moderate and rare conditions. This is despite the fact that environmental rarity and extremity are strongly correlated (r=0.84). Clearly common and rare species can both respond differently to environmental variables and differentially affect species richness while the responses differ between vascular and non-vascular plants.